Automated FileFeeds
Automated file feeds & cloud SFTP hosting for recurring partner data.
Why Automated FileFeeds
FileFeeds capture files from managed SFTP folders today, then automatically validate, transform, and deliver clean structured data into your systems without cron jobs, polling logic, or custom ETL pipelines.
End-to-End Setup in 7 Steps
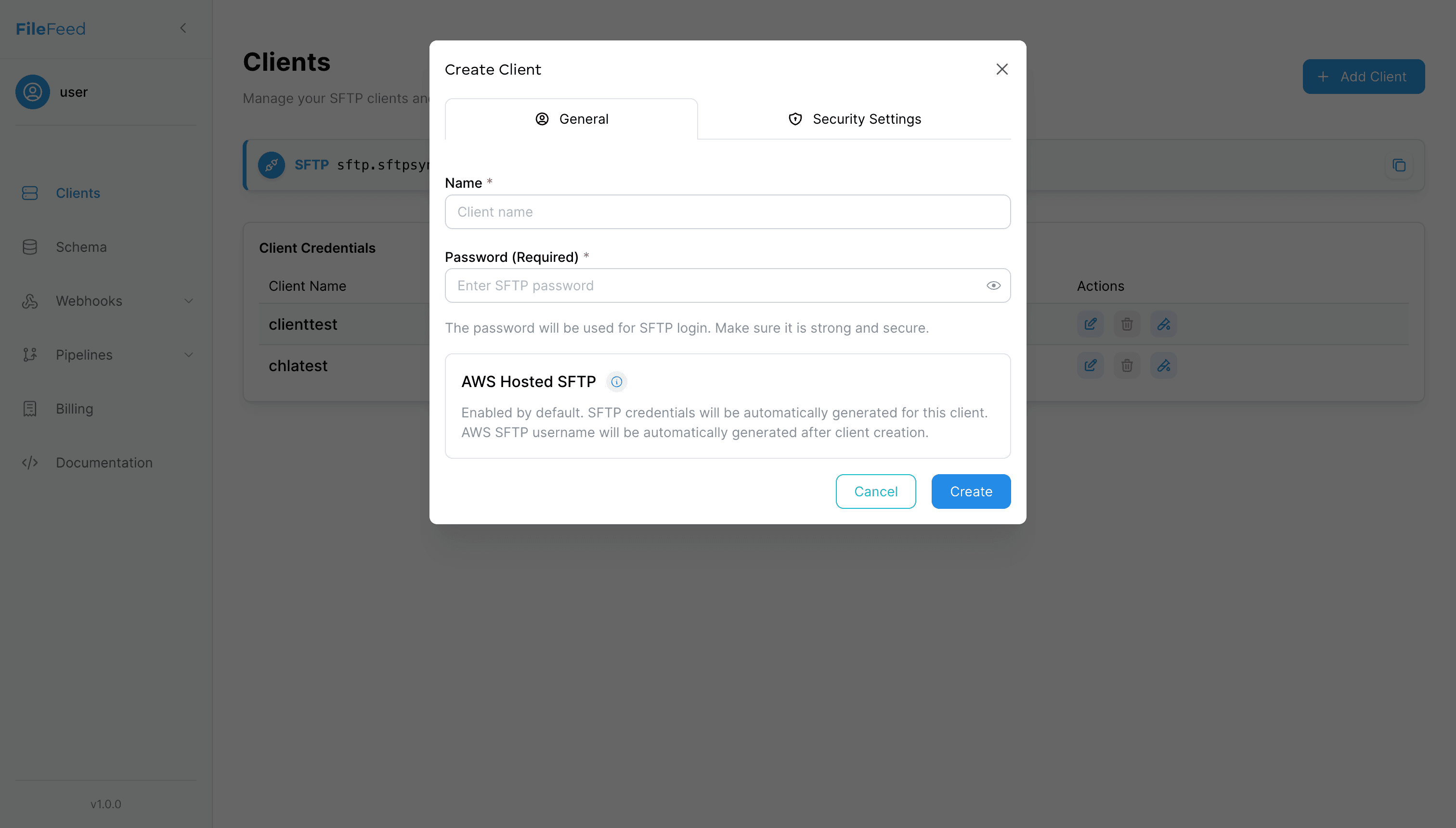
Step 1 · Set up Clients
Create a Client to provision a dedicated, secure SFTP space and credentials for each data source.
- • AWS‑hosted SFTP (managed)
- • Per‑client folders and credentials
- • IP allow‑listing
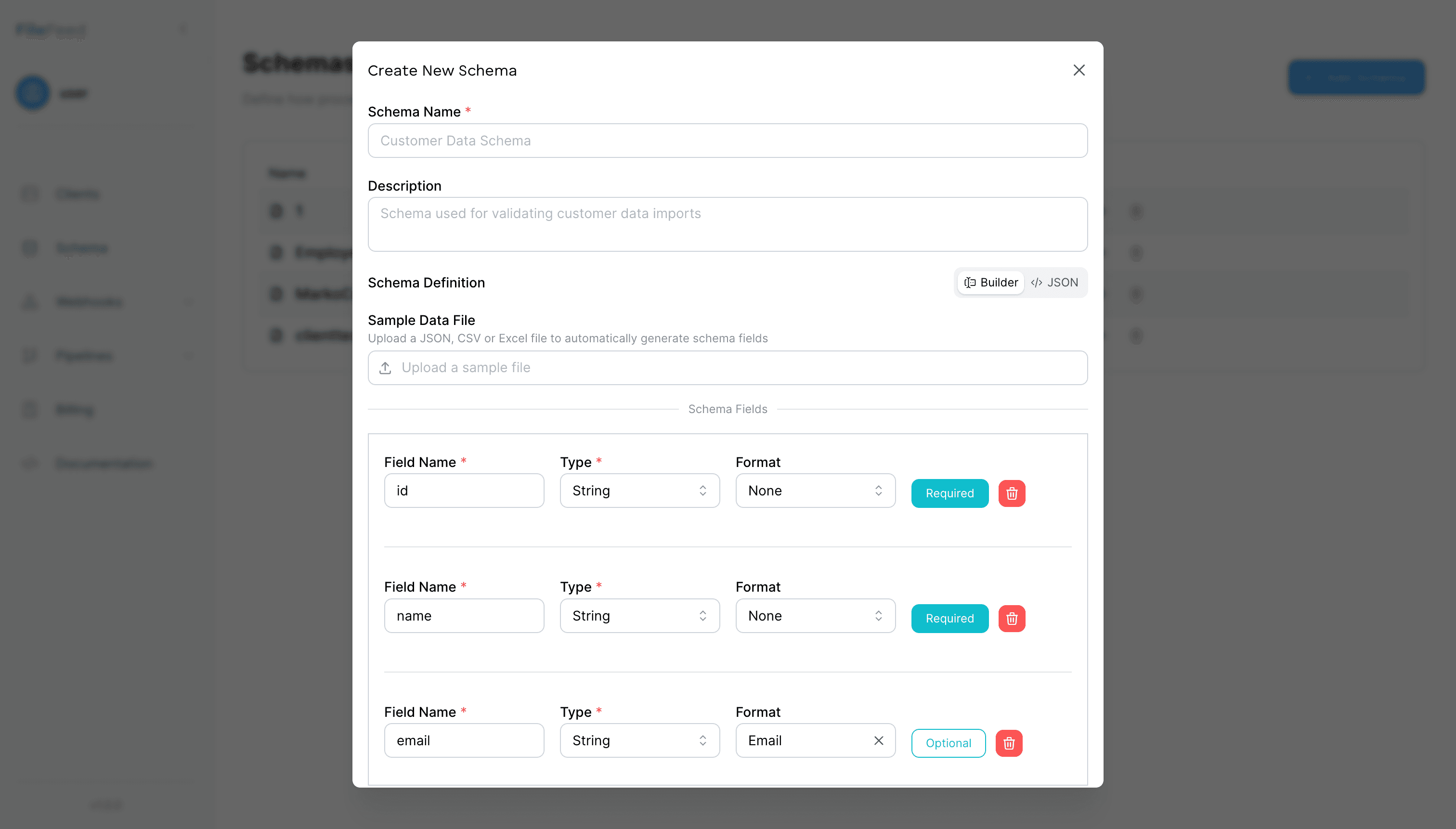
Step 2 · Define a Schema
Model the dataset you expect (fields, types, required, formats) using JSON Schema.
- • String, number, date, enum
- • Required and format checks
- • Reusable versions
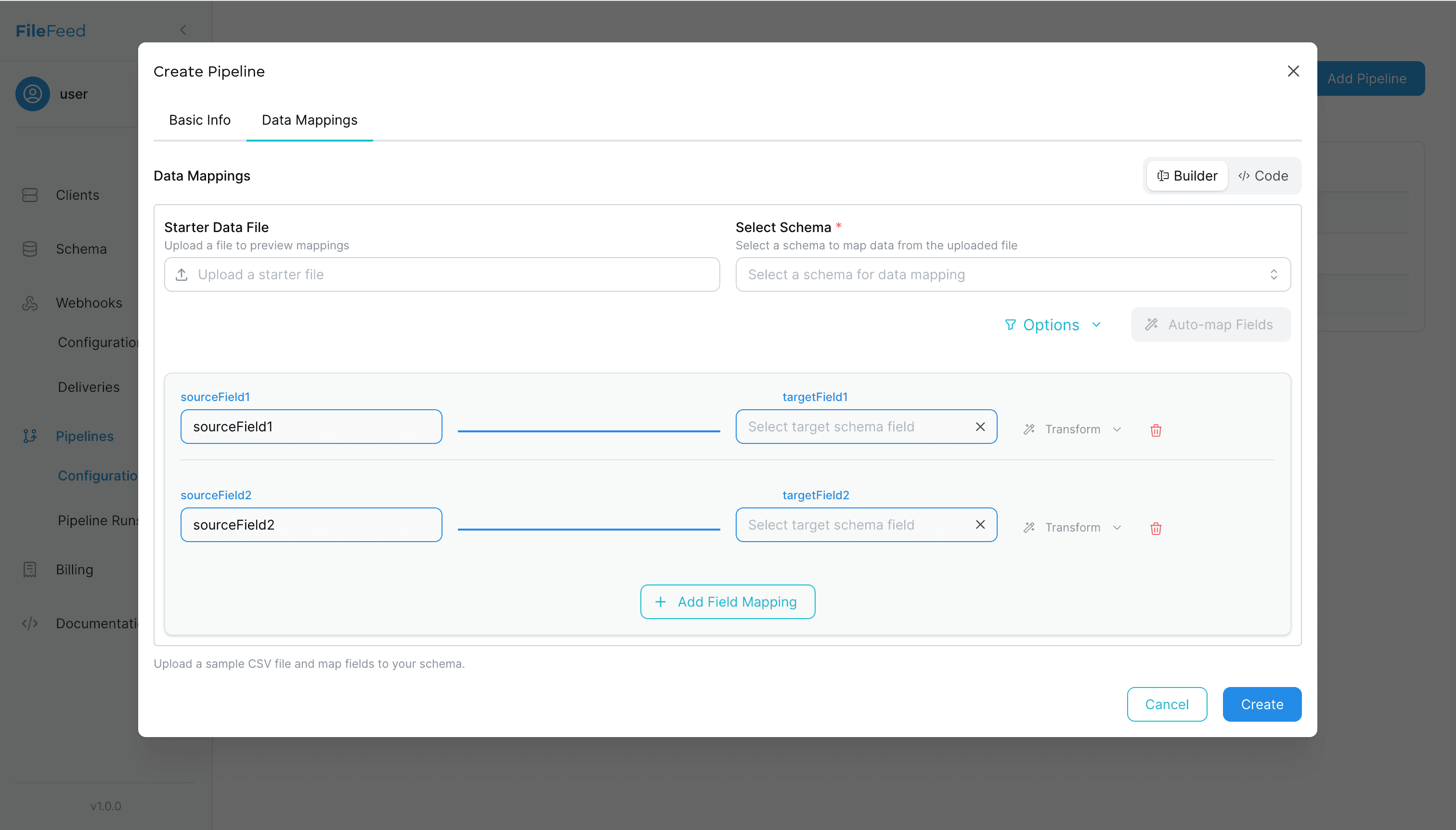
Step 3 · Create a Pipeline
Connect a Client + Schema and add field mappings, transforms, and CSV options.
- • Field mappings (source → target)
- • Transform functions
- • CSV options (delimiter, skip header)
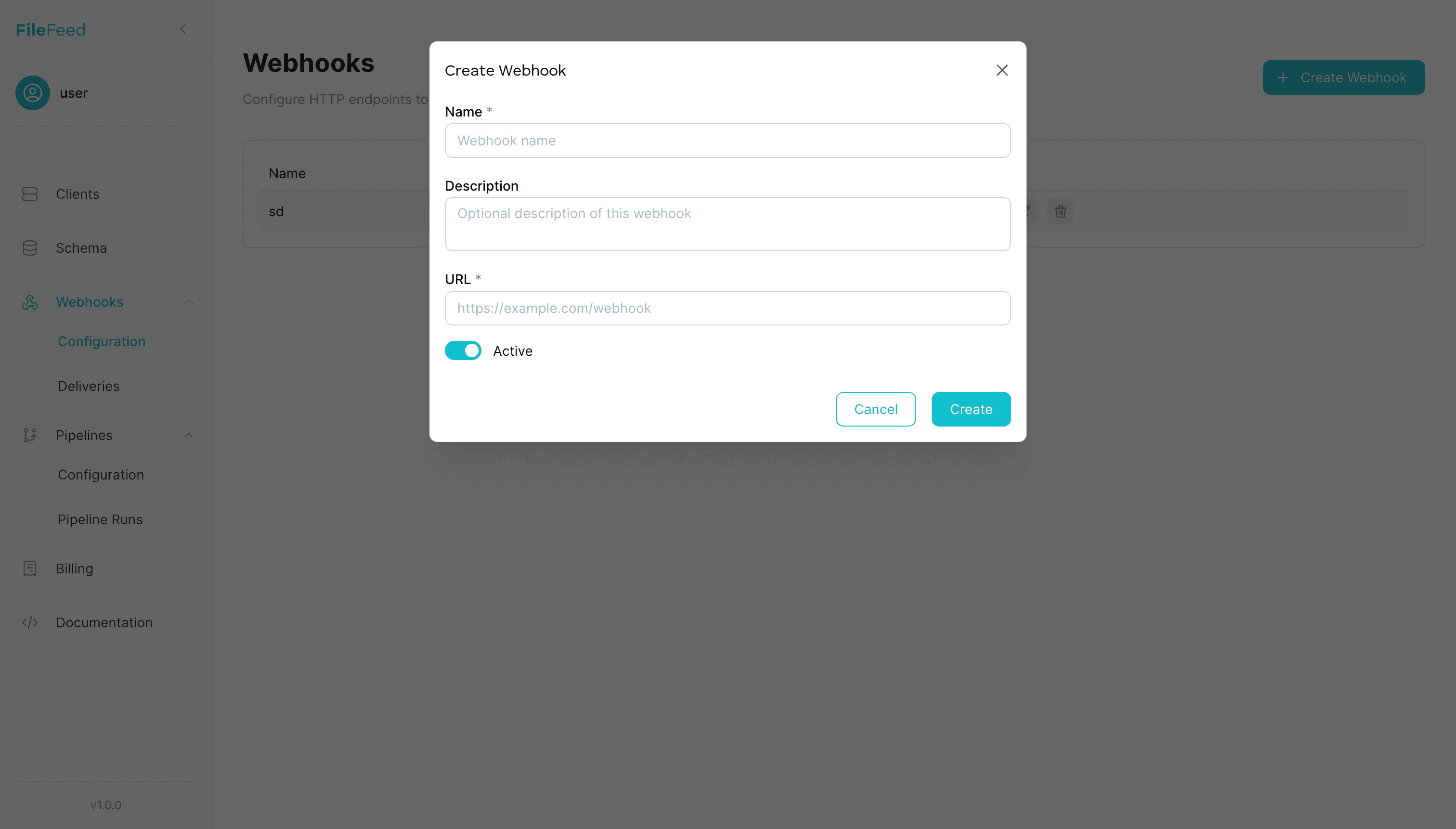
Step 4 · Register a Webhook
Receive signed events when files are received, processed, reprocessed, or fail.
- • Events: FILE_RECEIVED, FILE_PROCESSED, FILE_REPROCESSED, FILE_PROCESSING_FAILED
- • HMAC signature headers
- • Retry‑aware delivery with logging
Step 5 · Client uploads files
Clients upload to their SFTP folder manually or via scheduled exports from their systems.
- • SFTP ‘put employees.csv’
- • Scheduled nightly exports
- • Automatic pickup

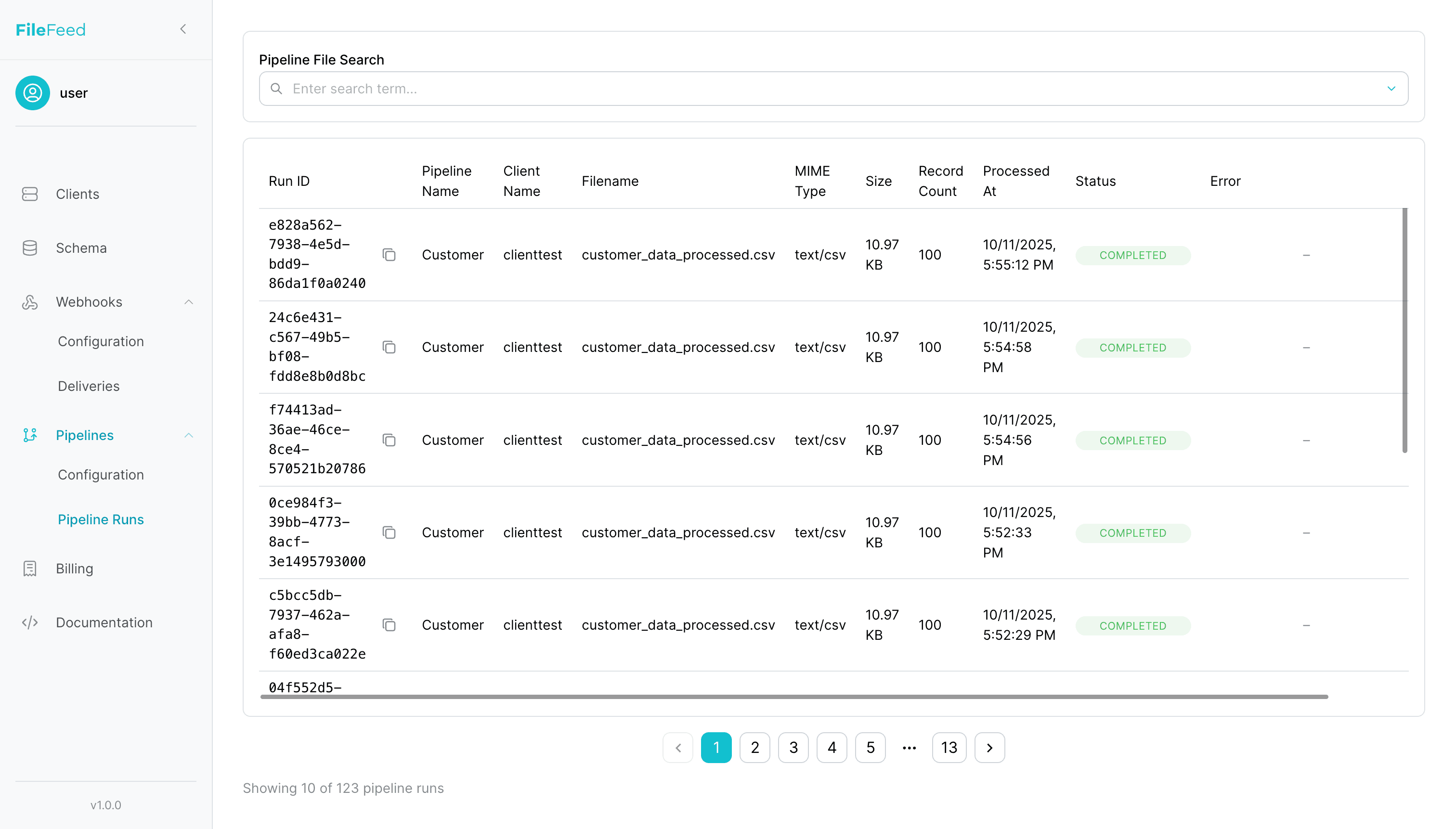
Step 6 · Monitor Pipeline Runs & Search trough files
Track run status, search files, and download original/processed files.
- • Statuses: pending → processing → completed/failed/acknowledged
- • Full-text document search (query by any word)
- • GET /pipeline-runs
- • Presigned downloads for originals/processed
Step 7 · Handle processed data
Process data in your backend using webhooks + REST API to fetch full JSON.
- • GET /files/pipeline-runs/:id
- • GET /files/json?clientName&fileName&pipelineId
- • PATCH /pipeline-runs/:id/status → acknowledged

Frequently Asked Questions
How is this different from running my own SFTP + cron jobs?
FileFeed hosts and isolates SFTP per client, validates every CSV, applies mappings/transforms, and notifies you via webhooks. You skip server upkeep, cron drift, and brittle parsing code.
Can I keep my own SFTP and still use FileFeed?
Yes. You can connect your existing SFTP or use our managed SFTP. Either way, the same validation and delivery pipeline runs.
What if partner files change headers or formats?
Schema validation catches drift, mappings normalize headers, and you can version schemas without breaking existing pipelines.
How do I get the processed data?
Receive webhook events (e.g., FILE_PROCESSED) and fetch JSON via REST, or pull presigned downloads of originals and processed files.
Is this a Flatfile or OneSchema alternative for recurring feeds?
Yes. FileFeed focuses on recurring SFTP/email file feeds with managed hosting, schema validation, and automation out of the box.
Ready to automate your file workflows?
Replace manual file processing and custom ETL scripts with automated, reliable data pipelines that scale with your business.
Start free • No setup fees • Enterprise-grade security